Для лечения множества заболеваний используют моноклональные антитела. Это большие молекулы, очень специфично распознающие свою мишень в организме человека. Их нельзя получить путем химического синтеза — они слишком сложно устроены. Для производства моноклональных антител используют биологические системы: вирусы, дрожжи, клеточные культуры и даже целые организмы. Методы получения антител можно разделить на две большие группы — гибридомные и дисплейные.
Метод гибридóм основан на получении особых клеток-гибридов, сочетающих в себе особенности В-лимфоцитов и опухолевых клеток. Для их наработки проводят иммунизацию животного (обычно мыши) — то есть вводят в него антиген. В ответ на это мышь вырабатывает множество специфичных к этому антигену В-лимфоцитов. Затем В-клетки выделяют из организма и объединяют с опухолевыми клетками (обычно — с клетками миеломы) в специальных условиях. Получившаяся гибридома «наследует» от В-лимфоцита способность вырабатывать антитела, а от клетки миеломы — способность к неограниченному количеству делений. В результате нескольких этапов селекции и скрининга (отбора наиболее специфично связывающихся с нужной мишенью гибридóм) отбирают самую подходящую гибридóму. Ее размножают, чтобы получить множество копий одной и той же клетки, которые будут нарабатывать только нужные антитела.
Главное преимущество метода гибридом в том, что это естественная, приближенная к живому организму система. На выходе получают полноценные молекулы растворимых антител, которые хорошо нарабатываются в больших масштабах. Но у этого метода есть и ограничения, главное из которых — небольшое количество молекул-кандидатов, которые удается проверить в одном раунде. Еще одна сложность — при таком подходе получаются антитела иммунизированного животного — например, мыши. Такие антитела чужеродны для человека, поэтому их необходимо гуманизировать («очеловечивать») — этим занимаются биоинформатики.
Технология секвенирования долго применялась для установления последовательности ДНК клеток одного вида (то есть «чистых культур»), а вот при попытке секвенировать материал из природных образцов возникало немало проблем. Пока не появилась метагеномика. Это направление занимается исследованием целых сообществ организмов, населяющих то или иное местообитание. Причем, оперируя метагеномными данными, ученые порой даже не имеют представления о внешнем виде и таксономической принадлежности изучаемых живых существ. Познакомимся с этой темой в деталях.
Последовательность шагов в метагеномном эксперименте
Начало
Собственно метагеномика стартовала с секвенирования отдельных ампликонов. И здесь, безусловно, самый известный маркер — ген 16s rRNA. По его последовательностям можно оценить разнообразие организмов сообщества. Так, благодаря этому методу в 1977 году ученые открыли новый домен жизни — Архей.
Но особенно преобразилась метагеномика с началом эры NGS. А именно стало распространяться полногеномное секвенирование и, соотвественно, Shotgun метагеномика. Она позволила определять таксономию и давать количественную оценку организмов вплоть до вида. Но главное ее отличие заключалось в том, что благодаря упорядочиванию множества различных частей генома каждого организма стало возможно выяснять еще и их функции в сообществе.
Шаг за шагом
Какова же последовательность современного метагеномномного анализа? Сначала ДНК образца нарезается случайным образом, после чего фрагменты секвенируются. Затем их необходимо упорядочить и реконструировать в согласованную последовательность, уже по которой можно будет сделать вывод о видовом составе микроорганизмов в сообществе и их роли в нем.
Поскольку данные состоят из коротких считываний (ридов), необходим этап сборки, который создает длинные последовательности из коротких. Далее требуется сортировка «каши» из последовательностей по принадлежности к таксономическим группам — биннинг. Есть несколько способов определить, какому микроорганизму принадлежит последовательность. Например, это может быть анализ частоты использования кодонов, поскольку известно, что данная характеристика зависит от набора транспортных РНК и представляет собой уникальный «почерк» микроорганизма.
Другой вариант — анализ степени покрытия: широко представленные в сообществе микроорганизмы обладают широким покрытием, слабо представленные — узким. Вместе собираются контиги с одинаковым покрытием.
Кроме того, контиги можно собирать по сигнатурным наборам генов — это гены, которые содержаться в одной копии в любом геноме прокариот. В сборке должен быть полный набор этих единичных генов. По итогу сборки получаются MAGи. MAG — это геном, собранный с помощью метагенома. Он представляет собой сборку одного таксона.
В дальнейшем полученные MAGи нужно аннотировать. Как правило этот процесс начинается с автоаннотации: программа разбивает MAGи на белок-кодирующие последовательности и определяет входящие в их состав гены. Однако автоматика часто оперирует не самыми последними данными и требует дальнейшей ручной обработки или комбинации различных программ.
Выводы
Таким образом, мы выяснили, что shotgun метагеномика — это работающий инструмент, чтобы узнать больше о микробном сообществе. Однако она не лишена недостатков. В сообществе могут встречаться гены, чья функция до сих пор не установлена, что оставляет в общей картине белые пятна. Кроме того, наличие определенных генов ничего не говорит об их экспрессии, и для получения этой информации нужна уже метатранскриптомика.
R был создан в 1992 году профессорами статистики Россом Ихака и Робертом Джентльменом, которые случайно встретились в Новой Зеландии и решили написать новый язык. Поскольку он наследовал языку S, то по первым буквам имен создателей новинку назвали R.
Ross Ihaka
Из Новой Зеландии R разлетелся по всему миру на жесткие диски студентов и преподавателей, специалистов по данным, биологов и биоинформатиков.
Практичность R сделала его идеальным языком программирования для обучения: новички могут получить немедленную визуализацию своих данных, выполнив самые простые операции. О базовых, но и самых полезных вещах в R поговорим дальше.
«Грамматика графики» ggplot2
10 июня 2007 года Хэдли Уикхем выпустил ggplot2. Сегодня это один из самых популярных пакетов в R. Его можно считать сильнейшей альтернативой базовому R в сфере построения графиков и визуализации. ggplot2 настолько самостоятелен, что его можно даже назвать отдельным диалектом R.
Hadley Wickham
gg в названии пакета означает «грамматику графики» — особый язык для описания графиков. Все графики состоят из трех компонентов: данных, сопоставления этих данных с визуальными элементами и геометрической формы, представляющей сопоставленные данные. Эти компоненты вместе с масштабом, статистическими преобразованиями и системой координат как раз составляют «грамматику графики», которая дает свободу в создании практически любой визуализации.
15 сентября 2016 года ggplot2 вместе с другими «вездесущими» пакетами, такими как dplyr для обработки данных и tibble для их хранения были объединены tidyverse. Этот набор пакетов переосмысливает операции с потоками данных в R и вводит оператор pipe « %>% », благодаря которому можно соединять программы и прогонять данные сквозь них. Да, большинство его возможностей доступны в базовом R, но tidyverse упрощает их использование и обеспечивает более интуитивно понятный и читаемый синтаксис.
Bioconductor — репозиторий для биоинформатиков
Robert Gentleman
В начале 2000-х после широкого распространения микрочипов, а потом с началом эры NGS началось лавинообразное накопление биологических данных. Вскоре стало очевидно, что и в R необходим специализированный проект для биоинформатиков. В 2001 году под руководством Роберта Джентльмена был запущен Bioconductor с глобальной целью разработки инструментов R для биоинформатики, особенно для анализа омиксных данных.
Сегодня Bioconductor — второй по величине репозиторий пакетов R после CRAN. В Bioconductor размещены самые загружаемые инструменты вычислительных биологов: от изучения дифференциальной экспрессии (DESeq2 и limma) до анализа генома (GenomicRanges).
RMarkdown — красиво писать не запретишь
Но как же эстетично представить полученные с помощью R результаты? Такую возможность нам дает язык разметки RMarkdown. Он позволяет легко сформировать отчет о работе.
Временная шкала возникновения культовых приложений в R
Система Rmarkdown была впервые представлена пакетом Knitr в 2012 году, а теперь поддерживается специальным пакетом rmarkdown.
Сгенерированный документ Rmarkdown представляет собой текстовый файл с расширением Rmd. В документе можно совместить код, результаты его исполнения и написанный текст. При желании вставить картинки, ссылки, видео и многое другое.
Rmarkdown — это система, которая позволяет авторам обмениваться не только необработанными данными, но и полностью воспроизводимыми пайплайнами, что увеличивает прозрачность в научных исследованиях. В практичности Rmarkdown можно легко убедиться, используя RStudio — она полностью поддерживает язык разметки.
Где писать код на R: интегрированная среда Rstudio
Помимо просто встроенной консоли R на компьютере можно применять многое другое: текстовые редакторы, интегрированную среду разработки (IDE), графические пользовательские интерфейсы (GUI) для развертывания своей работы в одном месте без каких-либо дополнительных окошек.
Одна из самых популярных сред разработки R, особенно у молодых программистов — RStudio. RStudio была первой IDE для R: ее запустили 28 февраля 2011 года.
RStudio задумывалась не только как редактор для написания и выполнения кода R, но и как растущая вселенная для разработки R и для выхода языка программирования за пределы статанализа. Само приложение доступно как в десктопной версии, так и для браузеров, подключенных к серверу. RStudio объединяет консоль, редактор с подсветкой синтаксиса с функцией дополнения по табуляции, среду с переменными, вывод графического изображения, историю команд и справку в одном рабочем пространстве.
Благодаря тому, что RStudio изначально поддерживает интерфейс с RMarkdown, она способствует проведению воспроизводимых научных исследований и грамотному программированию, позволяя сохранять код и дополнять его текстовой информацией.
А вы используете R в своей работе? Следите за выходом новых пакетов?
Сегодня искусственный интеллект (Artificial intelligence, AI) широко используется в науках о жизни: рациональный драг-дизайн, функциональная и структурная геномика и прочие омики, анализ медицинских изображений, предсказание третичной структуры белков и многое другое.
История ИИ
Принято считать, что сама область искусственного интеллекта зародилась в 1943 году, когда впервые была предложена математическая модель искусственного нейрона. А в 1956 году во время конференции в Дартмутском колледже Джон Маккарти предложил уже сам термин ИИ, введя его в академический оборот. В дальнейшем сфера претерпела несколько периодов бурного развития и полного застоя.
Американский информатик и автор термина «искусственный интеллект» Джон Маккарти. Источник
Окончательное возрождение искусственного интеллекта произошло в десятые годы XXI в., когда алгоритмы машинного обучения вошли без преувеличения в каждый дом: тут можно вспомнить системы распознавания лиц, обработки речи (Alexa, Siri), потребительских прогнозов (Netflix), машинного перевода (Google Переводчик). С тех пор сфера только развивается: лучшее подтверждение — нашумевший ChatGPT.
Искусственный интеллект, машинное и глубокое обучение
Обыватели часто смешивают понятия искусственный интеллект, машинное и глубокое обучение, оперируя ими как синонимами. Но на самом деле эти термины самостоятельны, хотя и вложены друг в друга по принципу матрешки.
Наиболее широко трактуется искусственный интеллект (ИИ, или AI).Под ним подразумеваются интеллектуальные системы, которые могут выполнять задачи, требующие творческого начала. Но пока машины не достигли уровня человеческого разума, и многие специалисты полушутя расшифровывают аббревиатуру ИИ как «имитация интеллекта».
Машинное обучение (Machine learning, ML) — одно из направлений ИИ, когда компьютеры могут сами распознавать шаблоны, находить закономерности в массивах данных и делать прогнозы. Яркий пример того, что ИИ не всегда тоже самое, что машинное обучение, — шахматы. В 1997 году действующий чемпион мира Гарри Каспаров потерпел поражение от IBM Deep Blue — ИИ, но без всякого машинного обучения.
Диаграмма Венна для области искусственного интеллекта (ИИ). Источник
Подобласть машинного обучения — глубокое обучение (Deep learning, DL). Это искусственные нейронные сети. Такие системы повторяют работу нейронов коры головного мозга, когда есть много слоев, и каждый слой получает переработанную информацию от предыдущего. Для глубокого обучения нужно гораздо больше данных, чем просто машинному обучению.
Далее поговорим о том, где ИИ нашел себя в биотехе. И начнем с растениеводства, где искусственный интеллект, по мнению специалистов, может решить проблему продовольственной безопасности. Потом рассмотрим лесное хозяйство и животноводство. А на закуску оставим, пожалуй, самое воодушевляющее направление — медицину.
Мониторинг состояния растений
В агротехе широко применимы алгоритмы компьютерного зрения (CV) на основе сверточных нейронных сетей (CNN). Компьютерное зрение может обнаруживать, автоматически идентифицировать и классифицировать объекты на изображениях, получаемых, например, с камер дронов. Как это работает?
Беспилотные летательные аппараты (БПЛА) облетают плантации по заданным маршрутам и осуществляют аэрофотосъемку, а ИИ анализирует и интерпретирует полученную информацию. Этот подход дает возможность удаленно мониторить состояние посевов, производить более точное прогнозирование урожайности, а также обнаруживать недостаток удобрений или наличие заболеваний и вредителей у сельскохозяйственных культур на огромных территориях.
А наземные роботы, «напичканные» датчиками, могут легко обнаружить сорняки и использовать ИИ для умного опрыскивания и прополки.Камера, установленная на машине-опрыскивателе, при детектировании сорного растения записывает его геолокацию, анализирует размеры и цвет, чтобы произвести расчет и внести точное количество гербицидов, необходимое для его уничтожения. Это позволяет сократить использование химикатов и сэкономить время.
Алгоритмы определяют степень зрелости томатов. Источник
Компьютерное зрение с высокой точностью определяет зрелость плодов и сроки их уборки. Уже созданы роботы c множеством датчиков и искусственным интеллектом, которые перемешаются по теплице. Проанализировав положение плодов в пространстве и степень их поспевания, машины осуществляют захват фруктов или овощей, а потом и сортировку. Роботизированные сборщики урожая смогут решить трудовую проблему, особенно ярко проявившуюся во время пандемии, когда фермеры столкнулись с острой нехваткой рабочей силы.
«Как соотносятся генотип и фенотип?» — одна из краеугольных проблем современной селекции растений. Традиционные инструменты фенотипирования основывались на ручном измерении отдельных фенотипических признаков небольшой выборки растений на определенных стадиях онтогенеза, что давало лишь ограниченную информацию и к тому же заставляло повреждать побеги.
Сегодня широкое распространение получило высокопроизводительное фенотипирование (High-throughput phenotyping, HTP), обеспечивающее цифровой автоматизированный анализ гигантских выборок растений для массовых селекционно-генетических экспериментов. HTP подразумевает оценку сразу множества признаков от клеточного уровня вплоть до целых растительных сообществ. Метод позволяет найти закономерности между морфологическими, химическими и физиологическими свойствами тысяч растений и условиями среды.
Как собирают большие данные для фенотипирования. Источник
Сбором данных при HTP занимаются беспилотные летательные аппаратами в сочетании с алгоритмами компьютерного зрения, а также наземные роботы, оснащенные несколькими датчиками и неинвазивными сенсорами, которые могут делать замеры на всем участке несколько раз в день или в течение всего сезона от всходов до созревания. Это приводит к огромному количеству пространственных и временных данных для анализа и хранения, эффективно разобраться с которыми помогает также машинное обучение.
Объединение результатов фенотипирования на основе изображений и информации с полевых датчиков с геномными и прочими омиксными данными о реакциях растений на условия среды (экспрессия генов, биосинтез метаболитов и т.д.) позволяет оптимизировать селекционный процесс и выявить новые фенотипы сельхозкультур, которые более эффективно используют ресурсы и устойчивы к меняющимся климатическим условиям.
Культура клеток растений in vitro
Чтобы быстро размножить растения в промышленных масштабах применяется биотехнологический метод — микроклональное размножение.
Диаграмма Исикавы, на которой перечислены основные факторы, влияющих на культуру тканей клеток растений и подлежащие моделированию с помощью ИИ. Источник
Здесь очень сложной задачей является подбор сред для культивирования тканей растений, поскольку нужно учесть множество факторов и их взаимодействие (фитогормоны, макро- и микроэлементы, витамины, аминокислоты). Модели ИИ могут имитировать и прогнозировать рост и развитие тканей растений in vitro в различных условиях для оптимизации питательных сред.
Животноводство
Животноводство — важный сектор сельского хозяйства и крупнейший в мире землепользователь. Чтобы поддерживать его рентабельность без вреда окружающей среде, отрасль должна производить больше с использованием меньшего количества ресурсов и вдобавок сокращать отходы.
Блок-схема процессов, которые подлежат оценке при LCA, на примере молочной фермы. Источник
Для интенсификации применяется LCA (Life-cycle assessment) — оценка жизненного цикла продукта. Это инструмент, позволяющий измерить экологический след на протяжении всех стадий от фермы до вилки: выращивание культур для производства кормов, здоровье животных, транспортировка, обработка и хранение пищевых продуктов.
Мониторинг создает большие данные, которые можно анализировать с помощью ИИ, чтобы переходить к более замкнутым циклам (за счет сокращения затрат и экономии ресурсов) и снижению выбросов парниковых газов.
Лесное хозяйство
Леса имеют планетарное экологическое значение, а древесина активно используется в хозяйстве. Однако возобновление не поспевает за обезлесением. Искусственный интеллект используется для анализа данных спутниковых снимков, фото с дронов и информации с наземных датчиков, чтобы прогнозировать рост и урожайность деревьев, а также места возгораний.
Схема работы системы мониторинга и предсказания лесных пожаров. Источник
В 2019-20 гг. Австралию охватила волна лесных пожаров, нанесших серьезный ущерб экосистемам: выгорело 190 тыс. кв. км леса на сумму более 20 млрд долларов. Оперативно была создана система Vesta Mark 2, котораяобъединяет исторические справки о пожарах за последние 40 лет, данные о состоянии лесного покрова и наиболее уязвимых местах возгораний с прогнозами погоды. На основе этой информации модель прогнозирует потенциальные очаги и скорость распространения пожара и шлет уведомления лесничим, чтобы они были готовы быстро выехать и потушить пламя.
Медтех
ИИ в медицине — популярное и динамично развивающееся направление, ведь оно напрямую касается здоровья человека. За годы работы медучреждений накапливается множество числовых и текстовых данных, например, результаты биохимических анализов, истории болезней или рентгеновские снимки пациентов. Алгоритмы могут анализировать эти массивы и находить скрытые закономерности, которые человек попросту не замечает.
Диагностика рака становится доступнее благодаря умному приложению на смартфоне. Источник
Особенно поражает воображение применение нейросетей для анализа медицинских изображений. Теперь, например, по обычной фотографии покровов тела, сделанной на смартфон, специальные мобильные приложения могут определять рак кожи без проведения биопсии и способствоватьранней диагностике заболевания.Недавно была создана модель ИИ, которая анализирует компьютерные томографии легких и может отличать раковые узлы от доброкачественных образований, что значительно упрощает работу врачам при постановке диагнозов.
Еще ИИ можно использовать для анализа данных из различных источников, таких как электронные медицинские карты и носимые устройства, для выявления закономерностей и корреляций, которые могут указывать на наличие определенной патологии или риск ее развития.
Машинное обучение и нейросети в RnD лекарств. Источник
Еще одна сфера: RnD лекарств. Разработка нового фармпрепарата — чрезвычайно длительный и дорогостоящий процесс, о чем мы недавно писали в статье. Однако отдельные его этапы можно ускорить с помощью ИИ, например, предсказание терапевтических мишеней. Использование нейросетей для интеграции разнообразных омиксных данных позволяет составить лучшее понимание механизмов болезней и определить потенциальные лекмишени.
ИИ пригоден и для рационального драг дизайна in silico. Химические библиотеки сегодня содержат миллиарды молекул, поэтому необходимы максимально эффективные подходы к виртуальному тестированию. Методы компьютерного обнаружения лекарств (CADD) способны значительно ускорить темпы скрининга новых препаратов. Например, платформа Deep Docking проводит экономичный молекулярный докинг и обеспечивает ускорение скрининга с помощью QSAR-модели в 50-100 раз. Это достигается за счет предварительного отбрасывания плохо «стыкуемых» молекул и окончательного докинга только ограниченного подмножества лигандов с наивысшими рангом. О современных подходах в медицинской химии можно послушать в лекции Яна Иваненкова.
Deep Docking ускоряет докинг во много раз. Источник
Еще больше о применении ИИ в медтехе, а также стартапах, которые активно развиваются в этой области, можно узнать из лекции Анны Костиковой, которую она прочитала в рамках курса «Биотех глазами инвесторов». Запись находится в открытом доступе на нашем ютуб канале.
Заключение
Таким образом, бум машинного обучения и нейросетей в нашем тысячелетии стал возможен благодаря доступности огромного количества данных, совершенствованию технологий их хранения, повсеместной цифровизации и все более высоким вычислительным мощностям. Сегодня буквально каждый день появляются новости об очередных достижениях в сфере искусственного интеллекта. Надеемся, что и в биотехе ИИ будет только процветать.
Бластим предлагает вместе знакомиться с ИИ. Начните в мае осваивать питон, а уже в конце лета приходите на продвинутый курс по ML. Так вы сможете быстрее выйти из зоны черного круга на диаграмме в начале нашей статьи в сторону тех, кто использует, исследует и разрабатывает ИИ! Успехов!
Описание метода впервые было опубликовано в 2016 году командой исследователей из Стокгольма. С его помощью ученые могут оценивать транскрипцию тысяч разных генов с разрешением 200 мкм и получать 2D-карты генной экспрессии.
Кратко опишем суть метода. Готовят матрицу-подложку с прикрепленными олиго(дТ)-праймерами, разделенную на участки диаметром 100 мкм. Праймеры включают в себя уникальные для каждого участка баркоды. На этой матрице ткань фиксируют, окрашивают, далее разрушают клетки — транскрипты выходят из клеток и гибридизуются с праймерами подложки. В итоге молекулы мРНК располагаются на матрице так же, как и в ткани. После проводят обратную транскрипцию, ткань ферментативно удаляют. Из тех транскриптов, что прикрепились, готовят библиотеку, которая отправляется на секвенирование. При этом пространственная информация сохраняется благодаря баркодам.
Главный результат анализа данных пространственного секвенирования — данные об экспрессии мРНК для каждого 100-микрометрового участка матрицы. Почему же это важно?
Обычное (bulk) секвенирование РНК даёт информацию о среднем состоянии большого количества клеток в кусочке ткани. Данные секвенирования единичных клеток, наоборот, показывают состояние каждой клетки по-отдельности. В свою очередь пространственное секвенирование транскриптома претендует на объединение обеих функций: можно оценить состояние небольших групп клеток в разрезе ткани. С появлением пространственной транскриптомики стало гораздо легче изучать сети межклеточных взаимодействий и зависимость состояния одной клетки от микро- и макроокружения в гетерогенных тканях.
Совместив несколько 2D-карт можно получить 3D-представление ткани, что даёт возможность моделировать ткани и органы. Это расширяет возможности наблюдения за динамическими процессами, например, эмбриональным развитием или ростом злокачественных опухолей.
В России этот метод еще не распространился. Мы знаем только одну лабораторию в Томске, где есть необходимые приборы. Однако по статистике PubMed, количество статей с упоминанием «spatial transcriptomics» увеличивается в 1.5 — 2 раза ежегодно начиная с 2017 года, а общее количество таких статей приближается к 400.
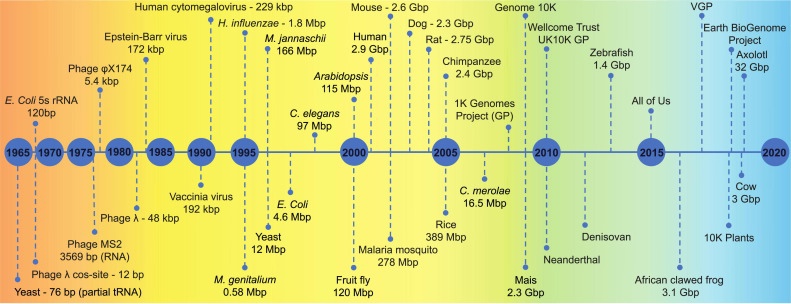
История геномики началась в 80х. Почти половину века ученые изучают структуру и функции генома, взаимодействия генов друг с другом и с окружающей средой. А возрастающая доступность технологий секвенирования с каждым годом расширяет возможности таких исследований. В зависимости от целей и методов выделяют несколько ключевых направлений геномики, о которых мы расскажем дальше.
Функциональная геномика
Функциональная геномика раскрывает весь путь реализации генома: от генов к определенным белкам и особенностям организма. Все осложняется тем, что один белок может влиять сразу на несколько признаков, на один признак может влиять несколько белков, а один ген (спасибо альтернативному сплайсингу) отвечать за несколько белков.
Структурная геномика
Как описать трехмерную структуру белка, зная последовательность оснований гена, который его кодирует? Здесь разберётся структурная геномика. Большую роль в исследованиях играет то, что ученые определяют структуры, кодируемые именно геномом, а не сосредотачивается на одном конкретном белке. В частности, в этом помогают уже изученные последовательности генов и относящиеся к ним структуры белков.
Эпигеномика
Если геном это сумма всех генов организма, то эпигеном представляет собой совокупность эпигенетических модификаций — факторов не меняющих последовательность оснований в ДНК, но от которых зависит работа генов. К ним относят, например, метилирование, гистоновые модификации, ацетилирование, фосфорилирование и т.д.
Эпигенетические модификации вовлечены в дифференцировку клеток и канцерогенез. Также эпигеномику используют в контексте биологии старения: у людей старшего возраста наблюдаются изменения профилей метилирования. Данные о модификациях получают различными способами: некоторые виды секвенирования (бисульфитное секвенирование, PacBio, ONT), иммунопреципитация хроматина (ChIP-on-chip, ChIP-Seq), гибридизация in situ, чувствительные к метилированию рестриктазы, идентификации ДНК-аденин-метилтрансферазы (DamID).
Сравнительная и эволюционная геномика
В этой области ученые работают с большими наборами геномов разных организмов, сравнивают их организацию и состав, выявляют геномные перестройки. Частый инструмент здесь пангеномы — объединением всех генов группы организмов. Моделирование эволюции, функциональная аннотация гена по последовательности, поиск гомологичных генов и блоков синтении, поиск молекулярных маркеров отбора — одни из примеров задач сравнительной геномики.
Популяционная геномика
Здесь изучают структуру генофонда популяции, его динамику во времени и причины изменчивости, ищут полиморфизмы, устанавливают связи между генетическими вариантом, фенотипом и средой обитания популяции. Уже описаны генофонды многих народов мира. Основные данные для анализа — генетические маркеры и их аналоги, в том числе последовательности митохондриальной ДНК и Y-хромосомы, полные последовательности генома, антропологические характеристики.
Метагеномика
Метагеномика использует генетические материалы организмов, полученные из образцов окружающей среды. Ученые анализируют видовой состав, филогению и разнообразие сообщества в образце по данным секвенирования. Чаще секвенируют не полный геном, а последовательность 16S рРНК у прокариот и 18S рРНК у эукариот.
Поиск ассоциаций
Метод полногеномного поиска ассоциаций (GWAS) подразумевает исследование генетических вариантов у разных людей с целью выяснить, связан ли какой-либо вариант с каким-либо признаком. В медицине это помогает находить генетические маркеры заболеваний. Ученые ищут однонуклеотидные полиморфизм (SNP), хромосомные перестройки (вставки, делеции, инверсии и т.д), а также вариаций числа копий генов (copy number variation, CNV) в геноме, возникающие из-за хромосомных перестроек.
Это далеко не все методы, которые применяют в современной геномике. Изначально геномные исследования были направлены на определение последовательностей ДНК, но за несколько десятилетий расширились до более функционального уровня — изучения генофондов целых популяций, профилей экспрессии и накопления огромного количества генетической информации. А умение обрабатывать данные стало ключевым навыком работы в этой области. Рассказываем основы на наших курсах «Анализ NGS-данных» в январе и «Анализ данных RNA-seq» к которому ещё можно присоединиться со скидкой.
1. В вакансии нельзя указывать прямые контакты hr-менеджера или других представителей компании. Мы против размещения любых телефонов или адресов электронной почты в тексте вакансии. Вакансии с контактами будут модерироваться, если после нашего напоминания работодатель не отредактирует текст в соответствии с правилами.
2. Тематика вакансии должна соответствовать тематике сайта — биотехнологии, IT в биологии и т.п. Запрещено предлагать соискателям экскорт-услуги, объявления на сайтах знакомств, игорный бизнес и т.п. Запрещается размещать вакансии, нацеленныена поиск исполнителя/покупателя для дипломных/научных работ. Вакансии, которые нарушают правила сайта и противоречат ценностям компании, будут удалены без предупреждения.
3. Описание вакансии должно быть полным. Рекомендуем подробно заполнять разделы, чтобы соискателям было понятно ваше предложение.
4. Не стоит дублировать вакансии. Если старое объявление устарело, удалите его и создайте новую вакансию. Можно отредактировать старую вакансию.
5. Рекомендуем тщательно проверить орфографию и пунктуацию — по тексту вакансии у соискателей складывается первое впечатление о работодателе.
6. По умолчанию мы деактивируем вакансию, которая была опубликована более года назад. Рекомендуем вовремя скрывать неактуальные вакансии или удалять их.
Рекомендации основателей Бластима по оформлению вакансии.
Мы предлагаем услуги по продвижению вакансии. Узнать подробности и сделать заказ можно по ссылке.